많이 읽은 경제뉴스 텔레그램 알람 봇 만들기 - AWS Lambda - ②
2020. 3. 22. 17:37ㆍAWS
이번 포스팅에서는 파이썬으로 네이버 경제 뉴스 크롤링을 하도록 하겠습니다.
저는 주피터 노트북을 사용하였습니다.
1. 네이버 경제 많이 읽은 뉴스
가장 많이 본 뉴스 메뉴는 경제지면까지 들어가지 않아도 뜨기 때문에 뉴스 기본 페이지에서 크롤링하셔도 됩니다.
- 네이버 경제면에서 우측에 가장 많이 본 경제 뉴스 TOP 10을 크롤링 하도록 하겠습니다.
- 다른 포털 사이트나 다른 지면의 뉴스를 원하시는 분들은 코드만 바꿔서 사용하시면 됩니다.

2. 가져올 목록의 HTML 태그 확인
우리에게 필요한 기사의 HTML태그가 어떻게 생겼는지, 필요한 태그가 무엇인지 확인합니다.
- https://news.naver.com/main/main.nhn?mode=LSD&mid=shm&sid1=101
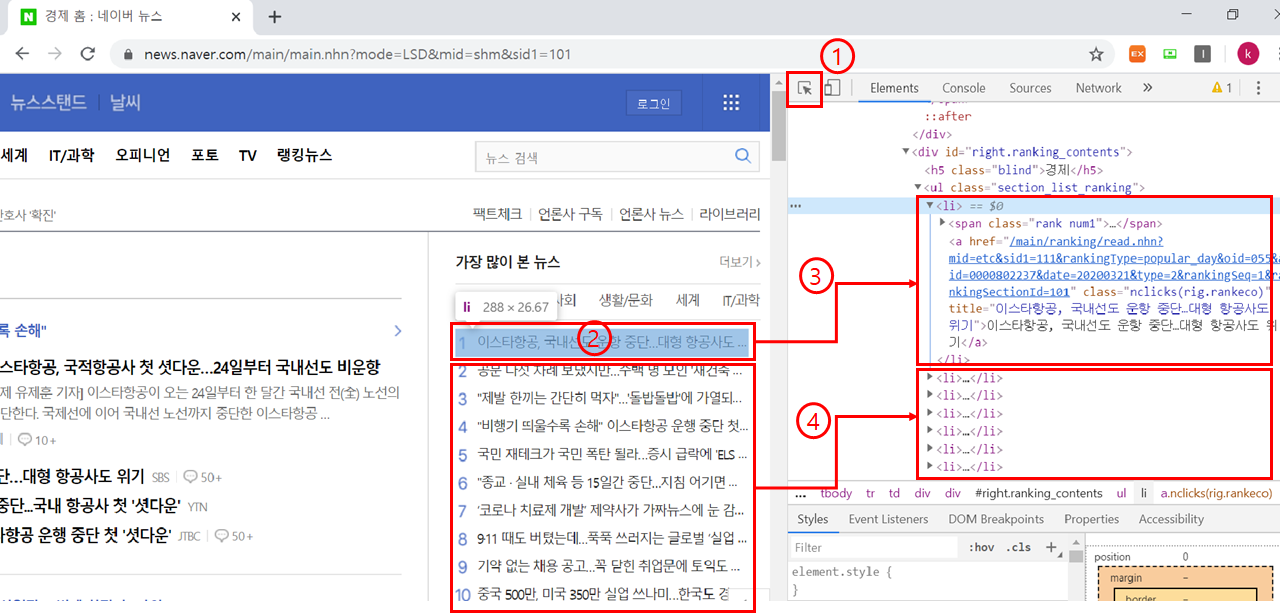
- 크롬에서 f12 를 누르시면 개발자 도구창이 우측에 뜹니다.
- 개발자 도구창을 띄운 상태에서 아래 그림의 1번 표시가 되어 있는 곳을 누르시고 그 상태로 2번 표시가 되어 있는 첫 번째 기사로 마우스를 갖다 대면 아래처럼 코드가 뜨게 됩니다.
- 3번과 4번에서 보면 알 수 있듯이 첫 번째 기사가 첫 번째 <li> 태그와 대응 되고 나머지 기사들이 차례로 각각 <li> 태그에 대응 된 다는 것을 알 수 있습니다.
3. 뉴스 크롤링 코드 작성
이제 주피터 노트북에서 코드를 작성해봅니다.
- 필요한 라이브러리들과 토큰 및 Chat_id 그리고 URL을 변수에 저장합니다.
from bs4 import BeautifulSoup
import telegram
import requests
import datetime
#필요한 라이브러리
token = "1234565977:AAE?uSv?6zxO?RR?kr8J-qIAt?VOe?Owh?Y"
#token (1편에서 확인했던 token)
receiver_id = 111111111
# Chat_id (1편에서 확인했던 Chat_id)
url = 'https://news.naver.com/main/main.nhn?mode=LSD&mid=shm&sid1=101'
- 텔레그램으로 메세지를 보내는 코드를 작성합니다.
- sendMessage 함수의 인수인 chat_id와 message를 텔레그램 bot의 sendMessage의 chat_id, text 변수에 입력합니다.
def sendMessage(chat_id, message):
bot.sendMessage(chat_id = chat_id, text=message)
#메세지를 보내는 함수
#chat_id 와 보낼 메세지 내용은 text가 필요하다.
- 네이버 뉴스에서 기사 제목과 URL을 크롤링 해오는 코드를 작성합니다.
- 왜 그런지는 모르겠으나 텔레그램에 메세지를 보낼 때 리스트 형태로 보내면 한글이 깨져서 전송이 됩니다. 깨지지 않게 하는 방법을 찾다가 한 문장으로 join시키면 깨지지 않아서 마지막 return 값을 join시켰습니다.
def url_title_extract():
req = requests.get(url)
html = req.text
soup = BeautifulSoup(html, 'html.parser')
#URL에서 HTML을 파싱해서 soup에 저장한다.
eco = soup.find_all('a', {'class':'nclicks(rig.rankeco)'})
#'a' 태그의 'class' 이름이 'nclicks(rig.rankeco)'인 것을 모두 찾아 eco에 저장한다.
#자세한 내용은 아래에서 설명
news_titles = []
#각각의 뉴스 제목을 담을 새로운 리스트를 생성한다.
for idx, new in enumerate(eco):
news_title = new.get_text()
news_titles.append('{}.'.format(idx+1) + news_title)
#eco에 담긴 내용을 차례로 하나씩 꺼내와서 get_text()를 통해 텍스트를 추출한다 .
#인덱스+1 값을 앞에 붙여서 1.첫 번째 기사 2.두 번째 기사 꼴을 만들어 준다.
news_urls = []
#각각의 뉴스 URL을 담을 새로운 리스트를 생성한다.
for new in eco:
news_url= new.attrs['href']
news_urls.append(" https://news.naver.com"+news_url)
#eco에 담긴 내용을 차례로 하나씩 꺼내와서 attrs['href']를 통해 URL을 추출한다.
result = []
#제목과 URL을 합칠 결과를 저장 할 리스트를 생성한다.
for i,j in zip(news_titles, news_urls):
result.append(i + j)
#zip을 사용해 각각의 리스트를 하나로 묶어 result에 저장한다.
return " ".join(result)
#리스트 형태인 result의 값들을 공백을 기준으로 join시켜주고 그 값을 return한다.
중간에 HTML 소스에서 태그와 클래스 이름을 사용해 추출을 하는 과정에서 BeautifulSoup을 사용하여 soup에 담겨있는 html을 prettify로 출력하게 되면 아래와 같이 기사가 묶여 있는 것을 확인 할 수 있습니다.
- <div>태그에 경제지면 뉴스들이 묶여있고 <ul>태그 안에 각 <li>로 기사가 한개씩 묶여있습니다.
- <li>태그 안에 <span> 태그를 사용하여 class가 "rank num1", "rank num2" ... 인 것들을 가져오게 되면 경제지면 외에 정치, 사회 등의 뉴스들도 같은 class 이름을 갖고 있기 때문에 모든 지면의 뉴스들이 추출되어서 사용 할 수 없습니다.
- <a>태그를 보면 class 이름이 "nclicks(rig.rankeco)" 라고 되어있는데 끝에 eco라고 붙어 있는 것으로 보아 경제를 뜻하는 것을 알 수있습니다. 실제로 다른 지면의 class이름을 찾아보면 "nclicks(rig.rankpol)", "nclicks(rig.ranksoc)" 와 같이 이름이 다르기 때문에 <a>태그를 활용하여 데이터를 추출하겠습니다.
<div id="ranking_101" style="display:none">
<h5 class="blind">경제</h5>
<ul class="section_list_ranking">
<li><span class="rank num1"><em>1</em></span> <a class="nclicks(rig.rankeco)" href="/main/ranking/read.nhn?mid=etc&sid1=111&rankingType=popular_day&oid=055&aid=0000802237&date=20200321&type=2&rankingSeq=1&rankingSectionId=101" title="이스타항공, 국내선도 운항 중단…대형 항공사도 위기">이스타항공, 국내선도 운항 중단…대형 항공사도 위기</a> </li>
<li><span class="rank num2"><em>2</em></span> <a class="nclicks(rig.rankeco)" href="/main/ranking/read.nhn?mid=etc&sid1=111&rankingType=popular_day&oid=214&aid=0001024673&date=20200321&type=2&rankingSeq=2&rankingSectionId=101" title="공문 다섯 차례 보냈지만…수백 명 모인 '재건축 총회'">공문 다섯 차례 보냈지만…수백 명 모인 '재건축 총회'</a> </li>
<li><span class="rank num3"><em>3</em></span> <a class="nclicks(rig.rankeco)" href="/main/ranking/read.nhn?mid=etc&sid1=111&rankingType=popular_day&oid=025&aid=0002985986&date=20200321&type=1&rankingSeq=3&rankingSectionId=101" title=""제발 한끼는 간단히 먹자"…'돌밥돌밥'에 가열되는 끼니 전쟁">"제발 한끼는 간단히 먹자"…'돌밥돌밥'에 가열되는 끼니 전쟁</a> </li>
<li><span class="rank num4"><em>4</em></span> <a class="nclicks(rig.rankeco)" href="/main/ranking/read.nhn?mid=etc&sid1=111&rankingType=popular_day&oid=437&aid=0000234157&date=20200321&type=2&rankingSeq=4&rankingSectionId=101" title=""비행기 띄울수록 손해" 이스타항공 운행 중단 첫 '셧다운'">"비행기 띄울수록 손해" 이스타항공 운행 중단 첫 '셧다운'</a> </li>
<li><span class="rank num5"><em>5</em></span> <a class="nclicks(rig.rankeco)" href="/main/ranking/read.nhn?mid=etc&sid1=111&rankingType=popular_day&oid=025&aid=0002985997&date=20200321&type=1&rankingSeq=5&rankingSectionId=101" title="국민 재테크가 국민 폭탄 될라…증시 급락에 'ELS 비상'">국민 재테크가 국민 폭탄 될라…증시 급락에 'ELS 비상'</a> </li>
<li><span class="rank num6"><em>6</em></span> <a class="nclicks(rig.rankeco)" href="/main/ranking/read.nhn?mid=etc&sid1=111&rankingType=popular_day&oid=055&aid=0000802233&date=20200321&type=2&rankingSeq=6&rankingSectionId=101" title='"종교 · 실내 체육 등 15일간 중단…지침 어기면 처벌"'>"종교 · 실내 체육 등 15일간 중단…지침 어기면 처벌"</a> </li>
<li><span class="rank num7"><em>7</em></span> <a class="nclicks(rig.rankeco)" href="/main/ranking/read.nhn?mid=etc&sid1=111&rankingType=popular_day&oid=032&aid=0002999092&date=20200321&type=1&rankingSeq=7&rankingSectionId=101" title="‘코로나 치료제 개발’ 제약사가 가짜뉴스에 눈 감는 이유">‘코로나 치료제 개발’ 제약사가 가짜뉴스에 눈 감는 이유</a> </li>
<li><span class="rank num8"><em>8</em></span> <a class="nclicks(rig.rankeco)" href="/main/ranking/read.nhn?mid=etc&sid1=111&rankingType=popular_day&oid=449&aid=0000188681&date=20200321&type=2&rankingSeq=8&rankingSectionId=101" title="9·11 때도 버텼는데…푹푹 쓰러지는 글로벌 ‘실업 대란’">9·11 때도 버텼는데…푹푹 쓰러지는 글로벌 ‘실업 대란’</a> </li>
<li><span class="rank num9"><em>9</em></span> <a class="nclicks(rig.rankeco)" href="/main/ranking/read.nhn?mid=etc&sid1=111&rankingType=popular_day&oid=214&aid=0001024680&date=20200321&type=2&rankingSeq=9&rankingSectionId=101" title="기약 없는 채용 공고…꼭 닫힌 취업문에 토익도 취소">기약 없는 채용 공고…꼭 닫힌 취업문에 토익도 취소</a> </li>
<li><span class="rank num10"><em>10</em></span> <a class="nclicks(rig.rankeco)" href="/main/ranking/read.nhn?mid=etc&sid1=111&rankingType=popular_day&oid=057&aid=0001434956&date=20200321&type=2&rankingSeq=10&rankingSectionId=101" title="중국 500만, 미국 350만 실업 쓰나미…한국도 경제 타격 3~4년">중국 500만, 미국 350만 실업 쓰나미…한국도 경제 타격 3~4년</a> </li>
</ul>
<a class="more_link" href="/main/ranking/popularDay.nhn"><span class="blind">가장 많이 본 뉴스</span>더보기</a>
</div>
- 날짜를 출력하는 코드를 작성합니다.
def date_extract():
current = datetime.datetime.today()
#datetime.today()를 활용해 현재 날짜와 시간을 current에 저장한다.
today_time = current.strftime("%Y/%m/%d") + " 많이 읽은 경제뉴스 TOP 10"
#datetime 데이터타입인 변수를 "%Y/%m/%d"형태의 문자열 형태로 변환한다.
#문자열 끝에 " 많이 읽은 경제뉴스 TOP 10" 라는 내용을 더해준다.
return today_time
- 실행시킬 main코드를 작성합니다.
- main코드는 이렇게 두셔도 되지만 Lamda에 올릴 때 형태가 조금 바뀌게 됩니다. 추후에 설명하겠습니다.
def main():
bot = telegram.Bot(token = token)
today_news = url_title_extract()
#url_title_extract()함수를 이용하여 추출한 제목과 URL을 today_news변수에 저장한다.
date = date_extract()
#date_extract() 함수를 이용하여 추출한 날짜를 date 변수에 저장한다.
date_news = date, today_news
for n in date_news:
bot.sendMessage(chat_id=receiver_id, text=n)
#날짜와 기사제목,URL을 차례로 메세지 전달한다.
3. 코드를 추합하여 실행 테스트
from bs4 import BeautifulSoup
import telegram
import requests
import datetime
token = "1068485977:AAE8uSv66zxOERR5kr8J-qIAtMVOeuOwhvY" #token
receiver_id = 984514882 # Chat_id
url = 'https://news.naver.com/main/main.nhn?mode=LSD&mid=shm&sid1=101'
def sendMessage(chat_id, message):
bot.sendMessage(chat_id = chat_id, text=message)
def url_title_extract():
req = requests.get(url)
html = req.text
soup = BeautifulSoup(html, 'html.parser')
eco = soup.find_all('a', {'class':'nclicks(rig.rankeco)'})
news_titles = []
for idx, new in enumerate(eco):
news_title = new.get_text()
news_titles.append('{}.'.format(idx+1) + news_title)
news_urls = []
for new in eco:
news_url= new.attrs['href']
news_urls.append(" https://news.naver.com"+news_url)
result = []
for i,j in zip(news_titles, news_urls):
result.append(i + j)
return " ".join(result)
def date_extract():
current = datetime.datetime.today()
today_time = current + datetime.timedelta(hours=9)
today_time = today_time.strftime("%Y/%m/%d") + " 많이 읽은 경제뉴스 TOP 10"
return today_time
def main():
bot = telegram.Bot(token = token)
today_news = url_title_extract()
date = date_extract()
date_news = date, today_news
for n in date_news:
bot.sendMessage(chat_id=receiver_id, text=n)
if __name__ == "__main__":
main()
- 코드를 실행하니 제 핸드폰의 텔레그램으로 뉴스목록이 도착했습니다.

다음 포스팅에서는 AWS-Lambda에 코드를 실행시키는 방법을 포스팅하겠습니다.
이전포스팅
2020/03/20 - 많이 읽은 경제뉴스 텔레그램 알람 봇 만들기 - AWS Lambda - ①
다음포스팅
'AWS' 카테고리의 다른 글
| 많이 읽은 경제뉴스 텔레그램 알람 봇 만들기 - AWS Lambda - ③ (1) | 2020.03.30 |
|---|---|
| 많이 읽은 경제뉴스 텔레그램 알람 봇 만들기 - AWS Lambda - ① (0) | 2020.03.20 |